SANIDHYA SINGAL
Machine Learning Engineer
Qualcomm Technologies, Inc.

Research Statement I'm particularly interested in Artificial Intelligence and Data Science. I enjoy learning and working on projects related to Machine Learning, Natural Language Processing, Information Retrieval and Recommender Systems. I firmly believe that research outcomes should be equitable to all sections of society, and intend to contribute to the same using novel artificial intelligence-based solutions.
News!
Received MicroMBA 2024 Program Certification from the Rady School of Management and UC San Diego Extended Studies.
Joined UC San Diego Health as a Machine Learning Engineer.
Graduated with a M.S. in Computer Science from UC San Diego.
Selected as a TA for DSC 232R: Big Data Analytics with Spark by Prof. Edwin Solares.
Selected as a TA for CSE 101: Design & Analysis of Algorithms by Prof. Miles Jones.
Selected as a TA for DSC 256R: Data Mining on the Web by Prof. Julian McAuley.
Selected as a TA for DSC 232R: Big Data Analytics with Spark by Prof. Yoav Freund.
Accepted into M.S. in Computer Science program at UC San Diego.
Presented a paper at ACM RecSys 2021.
Honoured with the "MVP" Award by Airtel Digital Limited.
-
Projects
Performed a detailed analysis to understand the limitations of the existing RAG systems, and identified and provided concrete examples of failure cases, along with future avenues of improvement. Examples included managing unrelated noise from external sources, handling mathematical reasoning, effectively integrating information, interpreting negative or missing statements, dealing with conflicting knowledge, and the difficulty in evaluations.
Implemented a custom transformer encoder and feedforward classifier from scratch, achieving 86.2% accuracy in political speech text classification. Pretrained a GPT-like transformer decoder, achieving a language model perplexity of 149.8 (out of a vocabulary of 5755) on political speeches. Enhanced model performance by further reducing perplexity by 38.2% using ALiBi for positional encoding and by 52% using Xavier/Normal initialization techniques.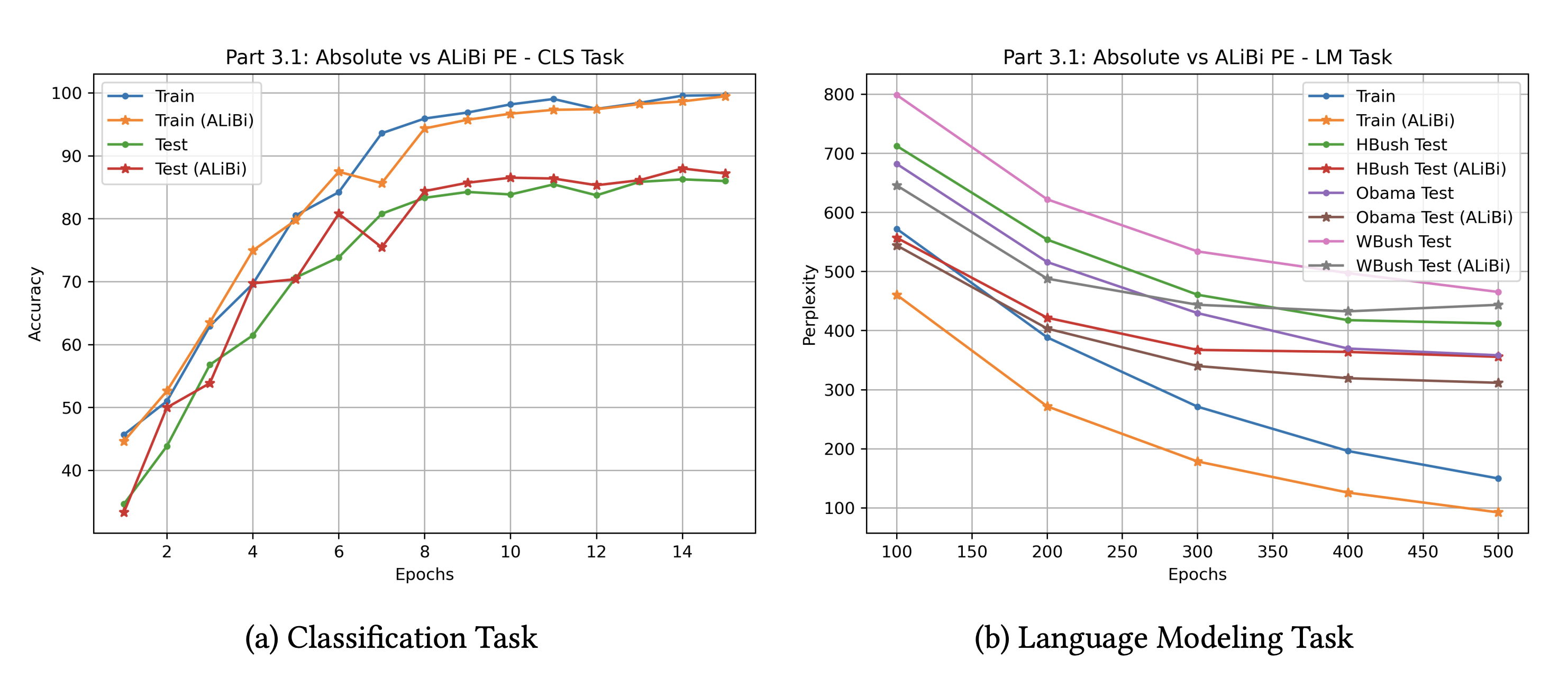
Investigated limitations of subquadratic-time architectures in handling long sequences, focusing on the lack of content-based reasoning. Performed a case study on Mamba, a novel neural network architecture integrating selective structured state space models (SSMs) to address this limitation. Mamba demonstrates improved performance on language processing tasks compared to existing subquadratic-time architectures.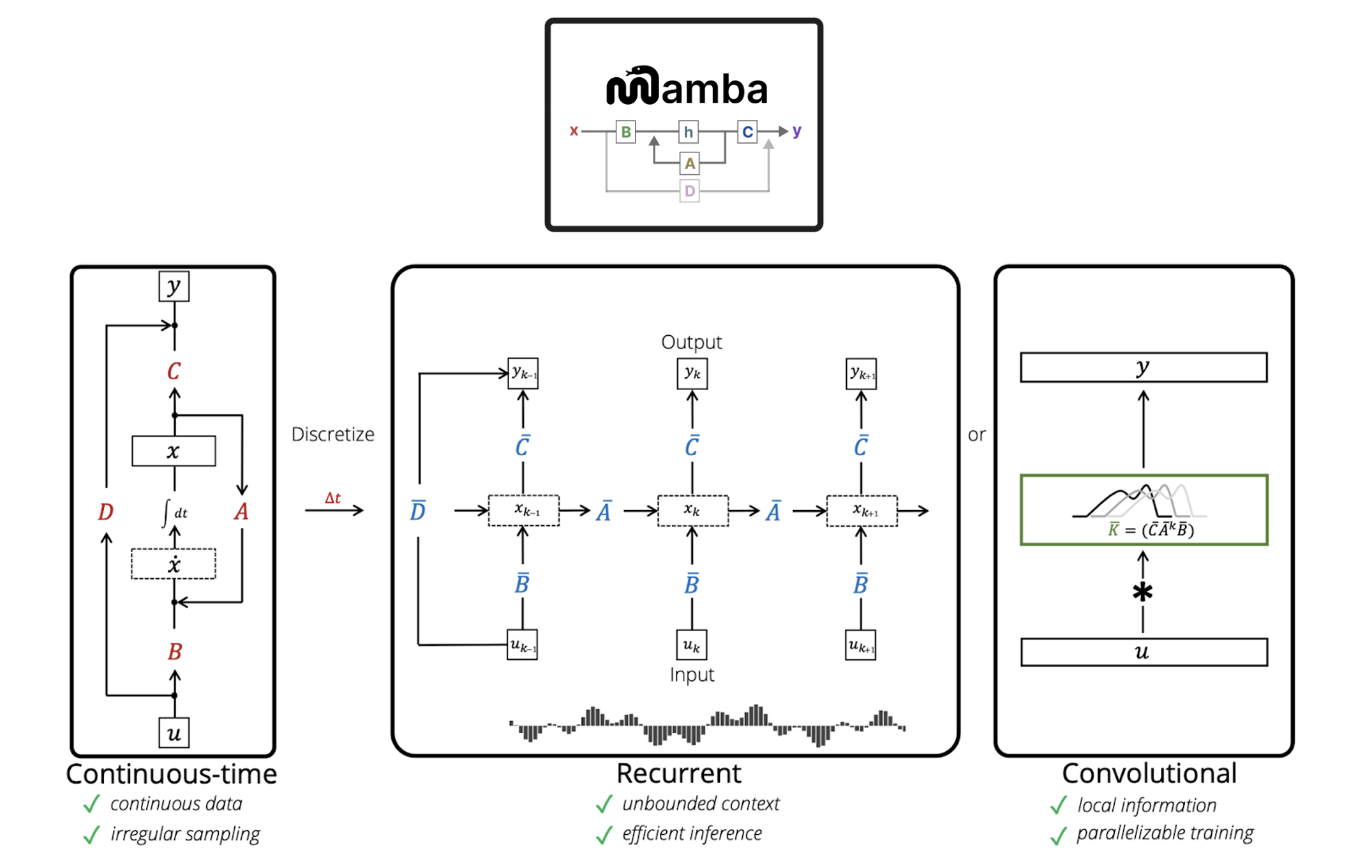
Showcased enhanced BLEU and ROUGE scores through the application of Retrieval Augmented Generation (RAG) on OpenAI’s LLM for closed-domain question answering in the field of medicine. Employed OpenAI Embeddings, FAISS Vector DBMS, and Flask for a web app which supports multi-modal input for patient interactions.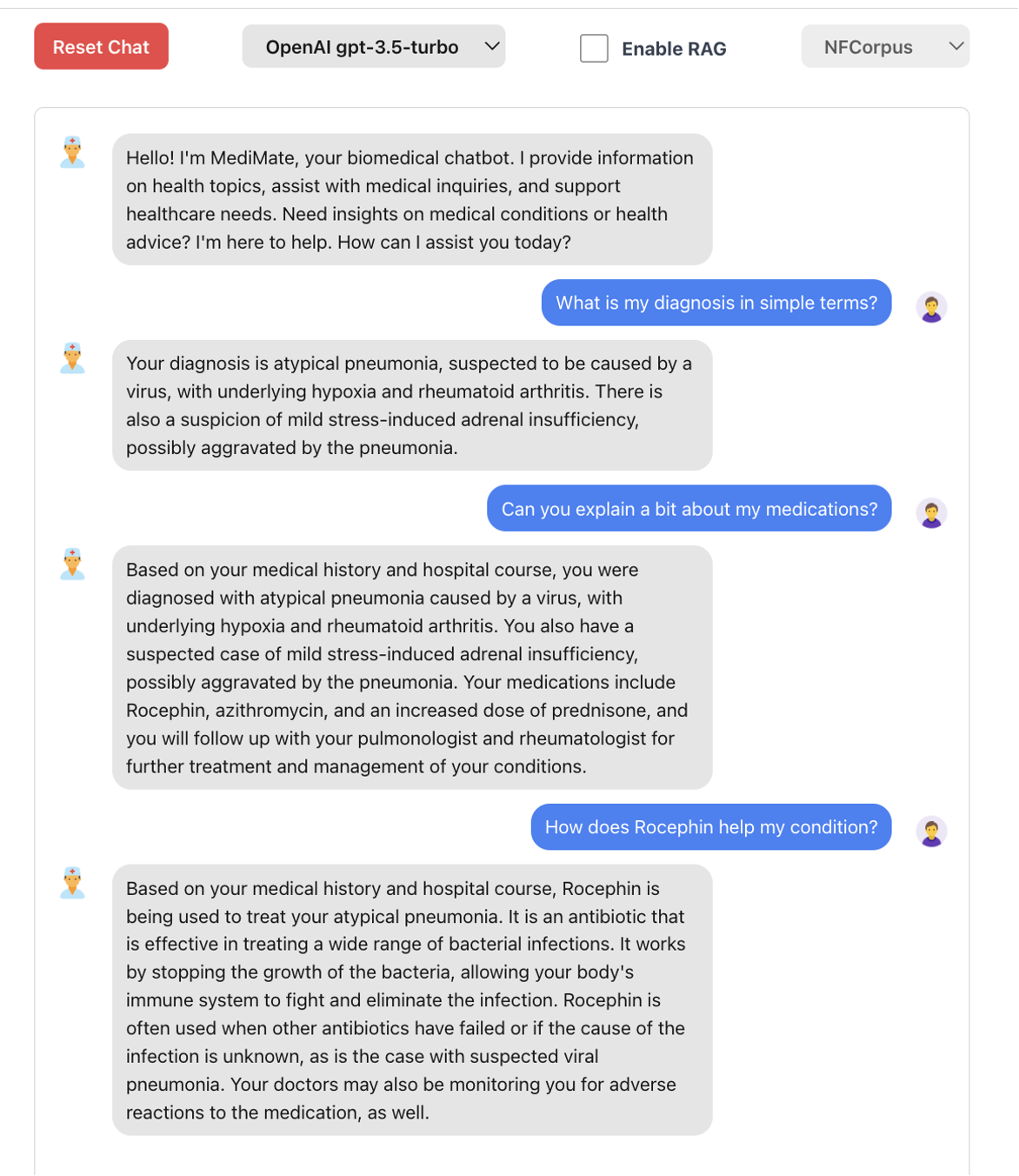
-
Publications
1.Singal, S. et al. 2021. Automatic Collection Creation and Recommendation. In Fifteenth ACM Conference on Recommender Systems (RecSys '21), Amsterdam, Netherlands. Association for Computing Machinery, New York, NY, USA, 633–638. DOI: 10.1145/3460231.3478865
 We present a collection recommender system that can automatically create and recommend collections of items at a user level. Unlike regular recommender systems, which output top-N relevant items, a collection recommender system outputs collections of items such that the items in the collections are relevant to a user, and the items within a collection follow a specific theme. Our system builds on top of the user-item representations learnt by item recommender systems. We employ dimensionality reduction and clustering techniques along with intuitive heuristics to create collections with their ratings and titles. We test these ideas in a real-world setting of music recommendation, within a popular music streaming service. We find that there is a 2.3x increase in recommendation-driven consumption when recommending collections over items. Further, it results in effective utilization of real estate and leads to recommending a more and diverse set of items. To our knowledge, these are first of its kind experiments at such a large scale.
We present a collection recommender system that can automatically create and recommend collections of items at a user level. Unlike regular recommender systems, which output top-N relevant items, a collection recommender system outputs collections of items such that the items in the collections are relevant to a user, and the items within a collection follow a specific theme. Our system builds on top of the user-item representations learnt by item recommender systems. We employ dimensionality reduction and clustering techniques along with intuitive heuristics to create collections with their ratings and titles. We test these ideas in a real-world setting of music recommendation, within a popular music streaming service. We find that there is a 2.3x increase in recommendation-driven consumption when recommending collections over items. Further, it results in effective utilization of real estate and leads to recommending a more and diverse set of items. To our knowledge, these are first of its kind experiments at such a large scale.
-
Timeline
-

Qualcomm Technologies, Inc.
Machine Learning Engineer
San Diego, California, USA
October 2024 - Present -

University of California San Diego Health
Machine Learning Engineer
San Diego, California, USA
August 2024 - October 2024 -

Laboratory for Emerging Intelligence, University of California San Diego
AI Application Programmer
San Diego, California, USA
June 2024 - August 2024 -

University of California San Diego
M.S. Computer Science and Engineering
San Diego, California, USA
Sept 2022 - June 2024
-